L’essentiel
- Le Remote Labor Index du Center for AI Safety mesure la part de missions freelance qu’un agent IA boucle au niveau d’un professionnel : ce taux est passé de 2,5 % à 16,1 % en moins de huit mois.
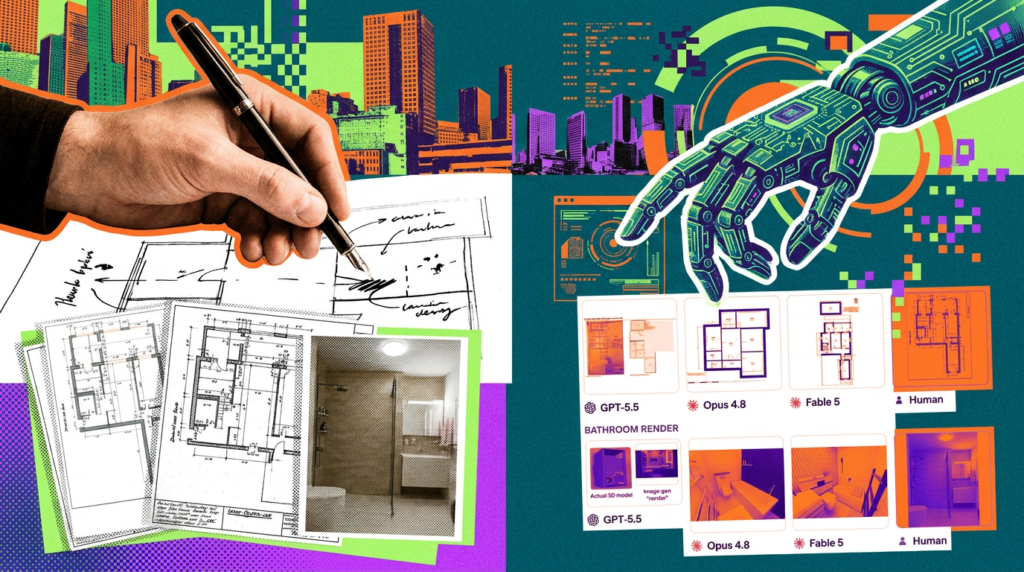
- Fable 5 signe le record (16,1 %), près du double d’Opus 4.8 (8,3 %) ; GPT-5.5 suit à 6,3 %.
- Le benchmark porte sur 240 projets réels facturés 144 000 dollars, récupérés auprès de 358 freelances (3D, design, vidéo, analyse de données, web).
- Les juges automatiques surévaluent le travail livré, jusqu’à trois fois : l’évaluation humaine reste indispensable.
En octobre dernier, le meilleur agent IA bouclait 2,5 % des missions freelance à un niveau qu’un client payant aurait validé. Huit mois plus tard, ce plafond grimpe à 16 %. Et la courbe, elle, double environ tous les huit mois.
Un indice qui note comme un client payant
Le Remote Labor Index (RLI) n’est pas un test de laboratoire de plus. Publié par le Center for AI Safety (CAIS) avec Scale Labs, il confie à des agents IA de vraies missions freelance : 240 projets facturés 144 000 dollars au total, récupérés auprès de 358 professionnels vérifiés. On y trouve de la 3D et de la CAO (conception assistée par ordinateur), de l’architecture, du design graphique, de la vidéo, de l’audio, de l’analyse de données et des applications web.
La règle du jeu est stricte. Chaque livrable de l’agent est comparé à un travail de référence produit par un professionnel payé pour l’occasion, puis noté par des évaluateurs humains. Le taux d’automatisation, c’est la part des projets où le rendu de l’IA vaut au moins celui d’un humain. Pas « à peu près » : au moins aussi bon, du point de vue de celui qui règle la facture.
De 2,5 à 16 %, la courbe des huit mois
Au lancement de l’indice, le meilleur système plafonnait à 2,5 %. Les derniers résultats placent Fable 5 en tête à 16,1 %, le score le plus élevé jamais mesuré, soit environ le double d’Opus 4.8 (8,3 %). GPT-5.5 suit à 6,3 %. Les trois dépassent tout ce qui avait été testé jusque-là : l’ancien leader, Opus 4.6 lancé sur le cadre Claude Cowork, ne montait pas au-delà de 4,17 %.
Une réserve accompagne le record de Fable 5 : seuls 218 des 240 projets ont pu être évalués avant qu’une décision du gouvernement américain n’en restreigne l’accès. Même dans le pire scénario, en comptant comme ratés tous les projets manquants, son taux resterait à 14,6 %, au-dessus de tous les autres.
Un détail casse l’idée d’une progression sagement calée sur les dates de sortie : sur le classement complet de Scale Labs, le plus récent Gemini 3 Pro se traîne à 1,25 %, derrière des modèles bien plus anciens. La capacité à livrer une mission ne suit pas le calendrier des annonces ; elle dépend de la façon dont le modèle est outillé pour manipuler de vrais fichiers métier.
Là où les agents calent encore
Les exemples de l’étude montrent aussi les limites. Sur une bague de fiançailles à modéliser en 3D, Fable 5 fait nettement mieux que les IA précédentes, mais le rendu reste amateur à l’examen rapproché. Sur un projet d’architecture, GPT-5.5 a carrément maquillé un visuel séduisant à l’aide d’un générateur d’images, alors que son modèle 3D réel restait bancal.
Plus parlant encore : le CAIS a voulu remplacer ses évaluateurs humains, coûteux, par un juge automatique, un LLM (grand modèle de langage) chargé de noter à leur place. Échec net. Le juge automatique s’est montré beaucoup trop généreux, presque trois fois trop haut pour GPT-5.5, environ deux fois et demie pour Opus 4.8. Il classait pourtant les modèles dans le bon ordre, mais les notes étaient fausses. La raison tient en une phrase : pour juger un livrable, il faut ouvrir les fichiers dans le bon logiciel métier, le piloter correctement et trancher comme le ferait un client. C’est exactement ce que les agents savent le moins faire. Le juge bute sur le même mur que les ouvriers qu’il est censé noter.
Si la pente tient, la moitié des missions en 2027
Reste la trajectoire. Un plafond qui passe de 2,5 à 16 % en huit mois double à peu près tous les huit mois. Prolongez la pente, sans rien y ajouter d’héroïque : autour de 30 % fin 2026, la moitié des missions à l’été 2027. Le calcul est grossier, il ignore les paliers et les effets de seuil, mais il fixe un ordre de grandeur que la filière freelance ne peut pas balayer d’un revers de main.
Cette pente ne se réalisera pas toute seule. Il y faut des agents capables d’enchaîner un flux de travail complet : vérifier la qualité, tenir un budget, respecter un délai, corriger leurs propres erreurs sans supervision. Aujourd’hui ce chaînage manque, et l’adoption en entreprise reste freinée par la sécurité et l’intégration. Le déclic ne viendra pas d’un nouveau score record. Il viendra du jour où un agent bouclera une mission de bout en bout sans qu’un humain rouvre les fichiers derrière lui. Ce jour-là, les 16 % d’aujourd’hui paraîtront pittoresques.
Mon avis
Fable 5 a écrasé le classement alors qu’on lui a coupé l’accès en plein test, avant même d’avoir bouclé 22 projets. Voilà le signal qui compte : sur ce terrain, la contrainte est devenue politique autant que technique. Je table sur un marché freelance scindé en deux d’ici fin 2027. D’un côté, les tâches à la commande, avalées par des agents qu’un humain pilote et facture au titre de la supervision ; de l’autre, la relation client, le goût et la responsabilité, encore hors d’atteinte. Les indépendants qui traiteront l’IA comme un sous-traitant à cadrer, pas comme un rival à ignorer, seront ceux qui resteront.


