L’annonce de KAIST a circulé en une ligne : une nouvelle technologie réduit les hallucinations des agents IA et améliore la précision des réponses jusqu’à 78 %. Beau chiffre, gros titre, dossier classé.
Mais réduire cette annonce au pourcentage, c’est manquer l’essentiel : ce correctif ne corrige rien dans le modèle lui-même. Il agit en amont, dans la base de données qui l’alimente.
Où agit réellement la correction
Quand un agent IA invente une réponse plausible mais fausse, le réflexe du secteur consiste à incriminer le modèle : pas assez de paramètres, entraînement insuffisant, garde-fous trop lâches. La course à la taille des grands modèles de langage (LLM, ces modèles entraînés sur d’immenses corpus pour produire un langage proche de l’humain) repose en partie sur ce postulat. Un modèle plus gros hallucinerait moins.
L’équipe du professeur Min-Soo Kim, à la School of Computing de KAIST, avec la startup GraphAI, prend le problème par l’autre bout. Leur réponse ne touche pas au modèle. Elle touche à la base de données qui l’alimente.
C’est tout le sens de leur travail, publié sous le titre AkasicDB: Demonstrating Omni RAG with a Unified Vector-Graph-Relational DBMS dans le Companion de l’International Conference on Management of Data. Le gain de précision annoncé, jusqu’à 78 %, et l’accélération du traitement, jusqu’à 20 fois, ne viennent pas d’un cerveau plus puissant. Ils viennent d’une plomberie repensée.
Pourquoi la base de données, et pas le modèle
Pour comprendre, il faut regarder comment fonctionne le RAG (Retrieval-Augmented Generation), la méthode qui sous-tend la plupart des agents d’entreprise. Le principe : on convertit la question de l’utilisateur et les documents en vecteurs, on récupère les documents sémantiquement proches, et on les passe au modèle pour qu’il rédige sa réponse à partir de cette matière.
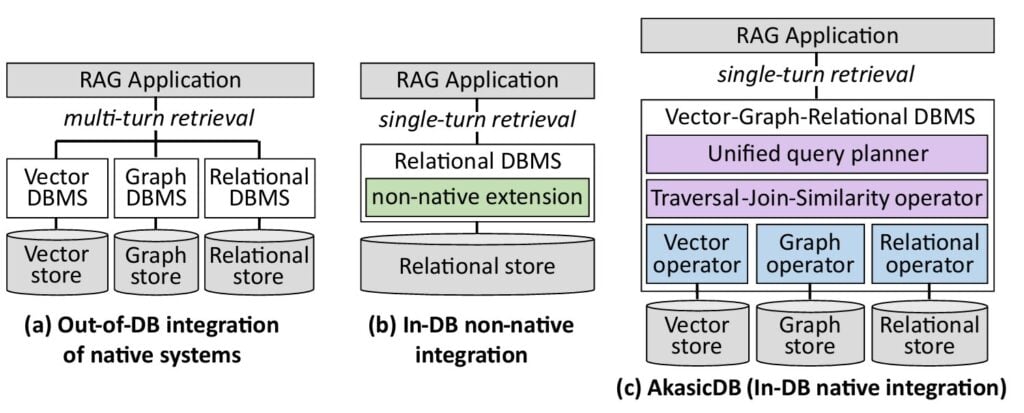
Le problème est que la donnée d’entreprise ne vit pas sous une seule forme. Elle se répartit entre des documents (du texte), des tables (des données structurées) et des relations entre entités (qui travaille avec qui, quel produit appartient à quelle gamme, quel contrat lie quelles sociétés). Chaque forme a sa base : base vectorielle pour le sens, base graphe pour les relations, base relationnelle pour les tableaux.
Quand un agent doit croiser ces trois mondes, il interroge des systèmes séparés et recolle les morceaux. C’est dans ces coutures que naissent les trous : une réponse mal ancrée, des relations perdues en route, et le modèle qui comble le vide en inventant. L’hallucination n’est alors pas un défaut d’intelligence. C’est un défaut d’accès à l’information.
AkasicDB : un seul plan d’exécution pour trois mondes
AkasicDB fusionne les fonctions des trois types de bases dans un seul système de gestion (DBMS). Là où l’approche conventionnelle fait tourner plusieurs bases en parallèle, KAIST traite une requête sur les trois modèles de données comme un plan d’exécution unique, via un planificateur de requêtes unifié et des opérateurs dédiés qui marient parcours de graphe, jointure et recherche par similarité. L’idée de coupler graphe et recherche vectorielle n’a rien d’inédit : Microsoft a popularisé son GraphRAG, publié en open source en 2024, pour réduire les hallucinations en adossant un graphe de connaissances au RAG. Le pari d’AkasicDB va plus loin, en réunissant les trois paradigmes dans un seul moteur plutôt qu’en juxtaposant des outils séparés.
Sur cette fondation, l’équipe a bâti une méthode baptisée Omni RAG. Son apport : mobiliser en même temps le sens des documents, les relations entre entités et les données structurées, au lieu de les récupérer en silos. Le modèle reçoit un contexte plus complet et mieux relié. Moins de trous à combler, donc moins d’inventions.
Le gain n’est pas cosmétique. Réduire les hallucinations en consolidant la donnée plutôt qu’en gonflant le modèle, c’est déplacer le centre de gravité du problème.
Ce que ça change pour qui orchestre l’IA
Pour un praticien qui assemble des agents au quotidien, la leçon est directe. Avant d’aller chercher un modèle plus gros et plus cher, regardez votre couche de récupération. Une part de vos hallucinations ne tient pas à la qualité du raisonnement, mais à une donnée éclatée que le modèle n’arrive pas à recoller.
Cette lecture a des conséquences économiques. Empiler les paramètres coûte cher, en calcul comme en énergie. Réparer l’infrastructure de données est un autre levier, souvent plus accessible, parfois plus durable. La fiabilité d’un agent se jouerait donc autant dans son architecture de stockage que dans son cerveau.
Restent les zones d’ombre, et il faut les nommer. Le chiffre de 78 % est un maximum (« jusqu’à »), mesuré dans un cadre de recherche : il dépendra des jeux de données réels et des charges en production. Fusionner trois paradigmes de bases dans un seul moteur soulève aussi des questions de montée en charge, de maintenance et d’adoption. Et un correctif sur la récupération ne supprime pas les hallucinations purement génératives, celles que le modèle produit même avec un contexte parfait.
Une autre carte du problème
Le mérite de ce travail dépasse son pourcentage. Il déplace la question : et si une part de la fiabilité des agents tenait moins au modèle qu’à l’ingénierie de données qui le nourrit ?
Si la piste tient hors du laboratoire, la prochaine vague de progrès sur les agents viendra peut-être moins des modèles géants que de l’infrastructure qui les alimente. Moins spectaculaire. Sans doute plus décisif.


