
Un éditeur sort le modèle d’IA le plus puissant de son catalogue. Et pour la première fois, ce n’est pas lui seul qui décide qui a le droit de s’en servir : c’est aussi la Maison Blanche.
OpenAI a dévoilé GPT-5.6 ce 26 juin, en trois versions baptisées Sol, Terra et Luna. Records de benchmark à l’appui. Mais ce lancement se joue ailleurs que dans les scores. Il se joue dans la liste, tenue secrète, de la vingtaine d’entreprises autorisées à y toucher.
L’essentiel
- OpenAI lance GPT-5.6 en trois variantes : Sol, la plus puissante ; Terra, équilibrée et deux fois moins chère que GPT-5.5 ; Luna, la plus rapide et la moins chère.
- Sol établit un record sur le test de codage Terminal-Bench 2.1, grâce à un nouveau mode « ultra » qui répartit le travail entre plusieurs sous-agents.
- Première du genre : à la demande de l’administration Trump, l’accès est réservé à une vingtaine d’entreprises validées par le gouvernement, dont les noms ne sont pas communiqués.
- La raison de cette prudence : les capacités du modèle en cybersécurité offensive, que le benchmark ExploitBench met en évidence.
Sol, Terra, Luna : trois paliers, une nouvelle nomenclature
OpenAI change sa façon de nommer ses modèles. Le chiffre, 5.6, désigne la génération. Les noms, eux, désignent des paliers de capacité appelés à évoluer chacun à leur rythme.
Sol est le modèle phare. Terra vise l’équilibre, avec des performances proches de GPT-5.5 pour moitié prix. Luna joue la vitesse et le coût plancher. Côté tarifs, cela donne, par million de tokens : 5 et 30 dollars en entrée et sortie pour Sol, 2,50 et 15 pour Terra, 1 et 6 pour Luna.
Sol gagne aussi un niveau de raisonnement supplémentaire, baptisé « max », et surtout un mode « ultra » qui ne se contente plus d’un seul agent : il répartit les tâches complexes entre plusieurs sous-agents. C’est ce mode qui lui permet d’établir un nouveau record sur Terminal-Bench 2.1, la référence pour l’agent de codage en terminal, à 91,91 %, contre 83,4 % pour GPT-5.5.
Le vrai signal n’est pas dans les benchmarks
Voilà pour la fiche technique. La suite est inédite. OpenAI ne met pas GPT-5.6 à la disposition de tous. Sur demande de la Maison Blanche, via son bureau de la cyber et celui de la politique scientifique, l’accès démarre en preview fermée, réservée à une vingtaine d’organisations dont la participation a été validée par le gouvernement. Les noms ne sont pas publics.
Rien de commercial dans cette retenue : il s’agit de sécurité nationale. Elle s’inscrit dans un décret présidentiel du 2 juin, qui ouvre une fenêtre d’évaluation de trente jours avant tout déploiement large. Sam Altman s’est rendu plusieurs fois à la Maison Blanche début juin et a discuté du modèle avec le secrétaire au Commerce, Howard Lutnick. Une sortie élargie est promise dans les prochaines semaines.
OpenAI ne cache pas son inconfort. Dans une note interne citée par la presse américaine, Sam Altman reconnaît que ce mode de déploiement n’est pas celui que l’entreprise privilégie sur le long terme. Et de faire savoir que ce type de validation gouvernementale préalable, à ses yeux, n’a pas vocation à devenir la norme.
ExploitBench : pourquoi ce modèle inquiète le gouvernement américain
Reste la question qui dérange. Pourquoi tant de prudence pour un assistant censé écrire du code et répondre à des questions ? La réponse tient dans un graphique qu’OpenAI a publié avec son annonce.
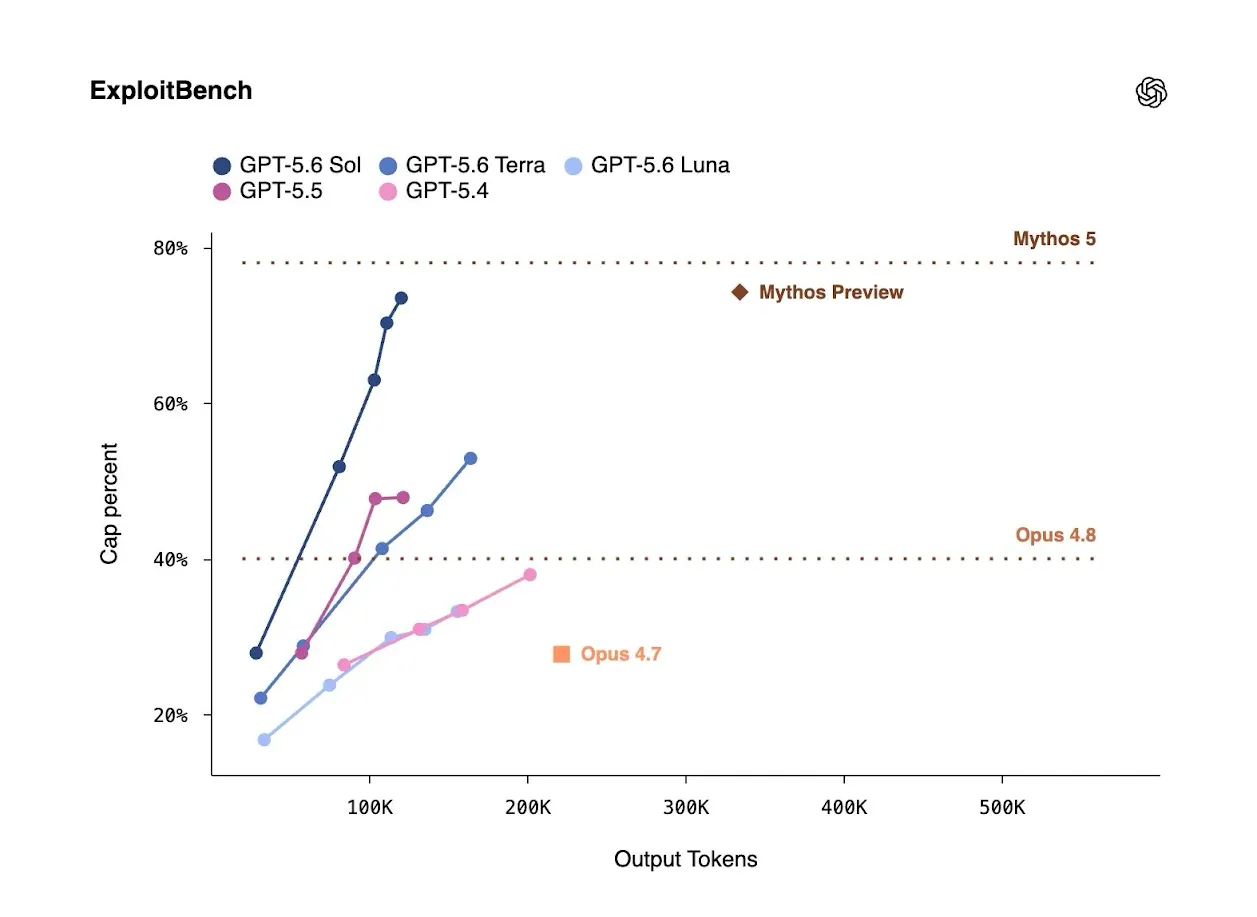
ExploitBench est un benchmark conçu par des chercheurs de Carnegie Mellon. Son principe : l’exploitation d’une faille se gravit par paliers. On part de la simple détection d’un bug, on monte vers la fuite d’informations, puis vers la prise de contrôle du flux d’exécution, jusqu’au sommet, l’exécution de code arbitraire sur la cible. Le test se joue sur des failles réelles du moteur V8 de Chrome, réputé difficile à attaquer.
Le graphique mesure deux choses. En abscisse, le nombre de tokens que le modèle dépense à raisonner, soit l’effort de calcul qu’on lui accorde. En ordonnée, le pourcentage de cette échelle d’exploitation qu’il parvient à gravir. La lecture est simple : plus une courbe monte vite et haut, plus le modèle va loin dans une chaîne d’attaque, et pour moins cher.
Le tracé bleu foncé, c’est Sol. Il grimpe plus vite que tous les autres et vient talonner les repères d’Anthropic, Mythos 5 et Mythos Preview. Ce dernier était jusqu’ici le seul modèle à pousser l’exploitation jusqu’à son terme. Surtout, Sol s’en approche en dépensant environ trois fois moins de tokens. Au passage, Sol, Terra et même GPT-5.5 dépassent Opus 4.7 et Opus 4.8, les modèles grand public d’Anthropic.
OpenAI assume le cadrage : selon l’entreprise, Sol est meilleur pour aider à trouver et corriger des vulnérabilités que pour mener seul une attaque de bout en bout contre une cible durcie. Dans son cadre de préparation interne, le modèle est tout de même classé « High » en cybersécurité, le cran juste avant le seuil critique.
Qui décide désormais quand un modèle sort ?
Ce lancement n’est pas qu’une montée de version. C’est le moment où l’arme et l’outil cessent d’être distinguables. Le même modèle qui aide un développeur à colmater une faille aide aussi à la trouver chez les autres, et l’écart entre les deux usages se réduit à un prompt.
Anthropic l’a déjà éprouvé à ses dépens. Le 12 juin, le Département du Commerce a interdit l’export de ses modèles cyber les plus avancés, Mythos 5 et Fable 5, à tout ressortissant étranger, forçant l’entreprise à les couper pour à peu près tout le monde. La nuance avec OpenAI tient en un mot : Anthropic a été stoppé après coup, quand GPT-5.6 est bridé avant même d’exister pour le public.
La question n’est donc plus de savoir si ces modèles savent attaquer. Ils savent. Elle est de savoir qui tient la liste de ceux qui ont le droit de s’en servir. Et pour l’instant, c’est l’administration Trump qui la tient.


