Dans le calcul quantique, tout le monde gagne. Du moins sur le papier de chacun. Chaque acteur publie ses propres chiffres, sous ses propres conditions, avec ses propres définitions du « taux d’erreur logique ». Le résultat ? Une cacophonie où plus personne ne peut comparer quoi que ce soit.
Le problème n’est pas technique, il est politique
On présente souvent les benchmarks comme des affaires d’ingénieurs : des protocoles, des intervalles de confiance, des courbes. La réalité est plus crue. Un banc d’essai partagé décide de ce qui compte comme « progrès », donc de qui a raison.
C’est exactement ce que vient bousculer FINAL-Bench Quantum, un classement ouvert publié sur Hugging Face. Sa promesse tient en une phrase : un même protocole, gelé et public, pour mesurer cinq familles de méthodes quantiques. Pas le banc d’essai d’un constructeur. Un banc d’essai neutre.
La nuance n’est pas cosmétique. Elle est le cœur du sujet.
Ce que tout le monde retient, et ce que tout le monde manque
La lecture dominante de ce genre d’annonce est prévisible : « enfin un classement pour savoir qui domine le quantique ». On cherche le vainqueur, la puce la plus rapide, le score le plus élevé.
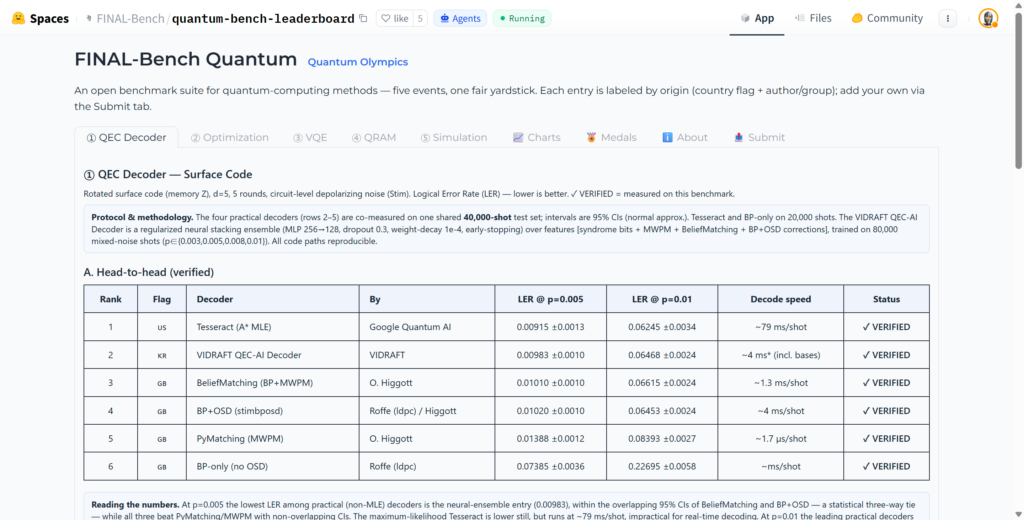
Or FINAL-Bench fait précisément l’inverse. Quand deux résultats tombent dans l’intervalle de confiance l’un de l’autre, il refuse de couronner un champion et parle d’égalité statistique. Une simulation reste étiquetée comme simulation ; le matériel réel est nommé avec sa puce. Aucune revendication d’« avantage quantique » n’est tolérée.
Autrement dit, ce projet ne vend pas un classement. Il vend une discipline. Et cette discipline est, par construction, désagréable pour le marketing.
Deux pistes pour ne pas comparer l’incomparable
Le dispositif repose sur une séparation simple, presque évidente une fois énoncée :
- Track A (Verified) : les méthodes sont mesurées sur place, sur un même jeu de test public et figé, avec des intervalles de confiance à 95 %. Ces chiffres sont directement comparables.
- Track B (Reported) : les chiffres sont repris des papiers ou annonces. Codes, modèles de bruit et matériel diffèrent : le projet dit clairement qu’ils ne sont pas comparables.
Cette frontière entre « mesuré ici » et « cité d’ailleurs » paraît anodine. Elle est en réalité le geste le plus subversif du projet. Car la plupart des communications industrielles vivent justement dans le flou entre les deux.
Cinq épreuves structurent le banc d’essai : décodage de correction d’erreur (QEC), optimisation de type Max-Cut, calcul d’énergie moléculaire (VQE), fidélité d’une mémoire quantique (QRAM), et simulation classique d’un circuit quantique. Pour chacune, une donnée passe souvent inaperçue mais change tout : la latence. Un décodeur « précis mais lent » peut être inutilisable en correction d’erreur en temps réel, où le décodage doit suivre le rythme du QPU (processeur quantique). La précision sans la vitesse n’est pas une demi-victoire. C’est un échec déguisé.
La neutralité comme preuve, pas comme slogan
N’importe qui peut écrire « benchmark neutre » sur une page. La vraie question est : qu’est-ce qui rend cette neutralité crédible ?
La réponse de FINAL-Bench est concrète. On y trouve des méthodes de Google, IBM, NVIDIA, de l’université chinoise USTC, de Riverlane, et jusqu’à une entrée coréenne (VIDRAFT) traitées sous le même protocole, les mêmes intervalles de confiance et les mêmes règles d’honnêteté. Le décodeur Tesseract est attribué à Google Quantum AI, PyMatching à son auteur O. Higgott. Chaque résultat porte un drapeau d’origine et le nom de ses auteurs.
Surtout, le projet s’impose une règle qui coûte cher : inclure les concurrents puissants même quand ils battent les propres entrées de l’hôte. C’est tout l’opposé d’un classement maison où le constructeur arrive comme par hasard en tête.
Un classement ne vaut que si l’on peut lui faire confiance. Et la confiance, ici, ne se décrète pas : elle se prouve ligne par ligne.
Pourquoi cela parle à ceux qui orchestrent des outils, pas seulement aux physiciens
On pourrait croire que tout cela ne concerne que les laboratoires de calcul quantique. Ce serait passer à côté de la leçon.
Quiconque travaille avec l’IA connaît le même piège. Les classements de modèles de langage débordent de scores choisis pour flatter celui qui les publie : jeu de test trié sur le volet, conditions opaques, comparaisons entre choux et carottes. Le précédent est documenté : début 2025, l’étude « The Leaderboard Illusion » a reproché au classement LMArena d’avantager les grands laboratoires, Meta ayant testé en privé vingt-sept variantes de Llama 4 pour n’en publier que le meilleur score. La mécanique est identique. Qui contrôle le protocole de mesure contrôle la perception du progrès.
FINAL-Bench Quantum propose, à sa petite échelle, une grammaire transposable :
- séparer ce qu’on a mesuré soi-même de ce qu’on cite ;
- afficher l’incertitude au lieu de la masquer ;
- refuser de transformer une simulation en exploit matériel.
Ce ne sont pas des détails de méthodologie. C’est une éthique de la mesure, et elle manque cruellement à l’écosystème IA.
Un banc d’essai peut-il rester neutre quand il devient un enjeu de pouvoir ?
Reste la question que tout classement crédible finit par poser. Un benchmark ouvert et honnête attire forcément les acteurs qui ont intérêt à le faire pencher. Plus il fait autorité, plus il devient un terrain de bataille.
La vraie épreuve de FINAL-Bench ne sera donc pas technique. Elle sera de tenir sa discipline quand les chiffres dérangeront les plus puissants de ses participants. La question n’est pas de savoir si un banc d’essai neutre est utile : il l’est, évidemment. Elle est de savoir combien de temps une mesure peut rester honnête une fois qu’elle décide qui écrit le récit.


