Un point. C’est l’écart qui sépare désormais le meilleur modèle ouvert du sommet fermé, sur les tâches de programmation qui s’étirent sur plusieurs heures. Et ce point-là, il faut le payer très cher.
Le match a changé de camp
Il y a quelques jours, nous décrivions GLM-5.2 comme le deuxième du code, coincé derrière un Fable 5 que personne ne peut réellement utiliser. C’était la bonne lecture à ce moment-là, mais elle a vieilli vite.
Depuis, le laboratoire chinois Z.ai (Zhipu AI) a publié les poids complets du modèle sous licence MIT, l’une des plus permissives qui soient. La comparaison pertinente a basculé : ce n’est plus Fable l’inaccessible qu’il faut regarder, mais Opus 4.8, bien réel et bien facturé. Et là, l’histoire devient autrement plus gênante pour la frontière fermée.
GLM-5.2 reste un modèle texte uniquement : 753 milliards de paramètres, dont 40 milliards actifs grâce à une architecture Mixture of Experts (un grand modèle découpé en sous-réseaux dont seule une fraction s’active à chaque requête). Sa principale évolution tient à la fenêtre de contexte, qui passe de 200 000 à un million de tokens. « Annoncer 1M de contexte est facile, le tenir sous pression d’ingénierie réelle l’est beaucoup moins », écrit Z.ai dans son billet d’annonce. C’est précisément ce terrain, les sessions longues et désordonnées d’un agent de code, que le modèle revendique.
À un point du sommet, sur les chantiers de plusieurs heures
Les chiffres donnent la mesure du rapprochement. Sur FrontierSWE, un test qui évalue des projets d’ingénierie ouverts s’étalant de quelques heures à plusieurs dizaines d’heures, GLM-5.2 obtient 74,4 %. Soit un seul point derrière Claude Opus 4.8, et légèrement devant GPT-5.5 d’OpenAI.
Sur Terminal-Bench 2.1, il bondit de 63,5 (pour GLM-5.1) à 81, à quelques points du sommet d’Anthropic. Sur PostTrainBench, où un agent doit améliorer de petits modèles sur un seul GPU H100, il dépasse GPT-5.5 et même Opus 4.7, et se classe encore deuxième derrière Opus 4.8. La plateforme indépendante Artificial Analysis, dont l’indice fait référence, confirme : avec 51 points sur son Intelligence Index, GLM-5.2 devient le modèle open weights le plus puissant du moment, devant MiniMax-M3, DeepSeek V4 Pro et Kimi K2.6, tous bloqués autour de 44.
Un point d’écart. Le genre de marge qu’on ne ressent pas sur un chantier réel.
Ce qui sépare vraiment l’ouvert du payant
C’est ici que la mise en regard devient intéressante. Opus 4.8 promet la performance de pointe et la tranquillité d’un service géré ; GLM-5.2 promet la même performance, ou presque, plus la propriété. Deux contrats très différents.
Le premier se loue. Sur OpenRouter, GLM-5.2 est distribué par neuf fournisseurs à environ 1,40 dollar le million de tokens en entrée et 4,40 en sortie. En face, Opus 4.8 affiche 5 dollars en entrée et 25 en sortie ; GPT-5.5 grimpe à 5 et 30. Selon le poste, la facture est trois à six fois plus légère côté ouvert. Et comme la licence est MIT, rien n’interdit de l’héberger soi-même, de l’auditer, de le fine-tuner sans demander la permission à personne.
L’arbitrage se déplace donc. Tant que le sommet fermé creusait un écart franc, payer la frontière se justifiait sans débat. À un point près, l’équation s’inverse : pour qui programme à grande échelle, automatise des agents de code ou traite des volumes industriels, justifier un coût cinq fois supérieur pour un point de benchmark devient un exercice difficile. La frontière fermée ne disparaît pas. Elle perd simplement son évidence.
Là où la frontière garde l’avantage
Ce rééquilibrage n’efface pas les nuances, et elles sont réelles. Sur les marathons extrêmes, GLM-5.2 décroche nettement : sur SWE-Marathon, qui empile des tâches comme la construction de compilateurs ou l’optimisation de kernels, il n’atteint que la moitié du score d’Opus 4.8. Le « un point » des tâches de quelques heures devient un gouffre dès qu’on passe aux dizaines d’heures.
Le raisonnement pur reste aussi en retrait. Sur Humanity’s Last Exam, GLM-5.2 cède une dizaine de points à Opus 4.8 et environ cinq à Gemini 3.1 Pro ; il traîne également sur GPQA-Diamond, un test de questions scientifiques. Les mathématiques font exception, avec 99,2 % sur AIME 2026. En usage agentique hors code, le tableau est mitigé : quasi à égalité avec Opus 4.8 sur le test d’outils MCP-Atlas (du nom du protocole MCP, qui standardise la façon dont un modèle appelle des outils externes), mais largement distancé sur Tool-Decathlon.
Dernier point à intégrer dans le calcul de coût : le modèle est gourmand. Artificial Analysis relève 43 000 tokens de sortie par tâche, contre 26 000 pour GLM-5.1. À tarif unitaire imbattable, GLM-5.2 consomme plus de tokens pour arriver au résultat. L’écart de prix réel se resserre donc un peu une fois la facture totale posée. Moins spectaculaire que le tarif affiché, mais toujours largement à l’avantage de l’ouvert.
Le sommet n’est plus un sanctuaire
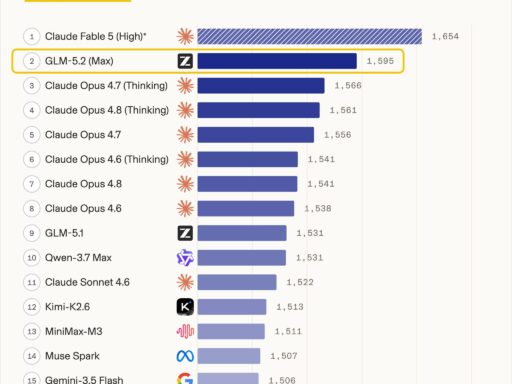
Reste l’image qui résume le basculement. Sur le classement Code Arena WebDev, qui mesure le développement front-end agentique, GLM-5.2 se hisse à la deuxième place, derrière le seul Fable 5 de Claude. Performance d’autant plus notable que le modèle ne lit pas les images, un atout qu’on croyait indispensable pour bien programmer une interface.
GLM-5.2 n’a pas rattrapé les leaders, et ce n’est pas le sujet. Ce qui change, c’est qu’un modèle qu’on peut télécharger, héberger et modifier librement campe désormais à un point d’un sommet qu’on ne peut que louer au prix fort. Pour le praticien qui orchestre l’IA au quotidien, l’enjeu ne se résume plus à désigner le meilleur modèle : il se chiffre, en euros et en dépendance, sur ce dernier point d’écart.