Anthropic occupe les cinq premières places du classement Arena de juin 2026. C’est le genre de chiffre qui fait les gros titres. Et c’est exactement pour ça qu’il faut s’en méfier.
Car le consensus tient en une phrase : une firme écrase la concurrence. La vraie information est ailleurs.
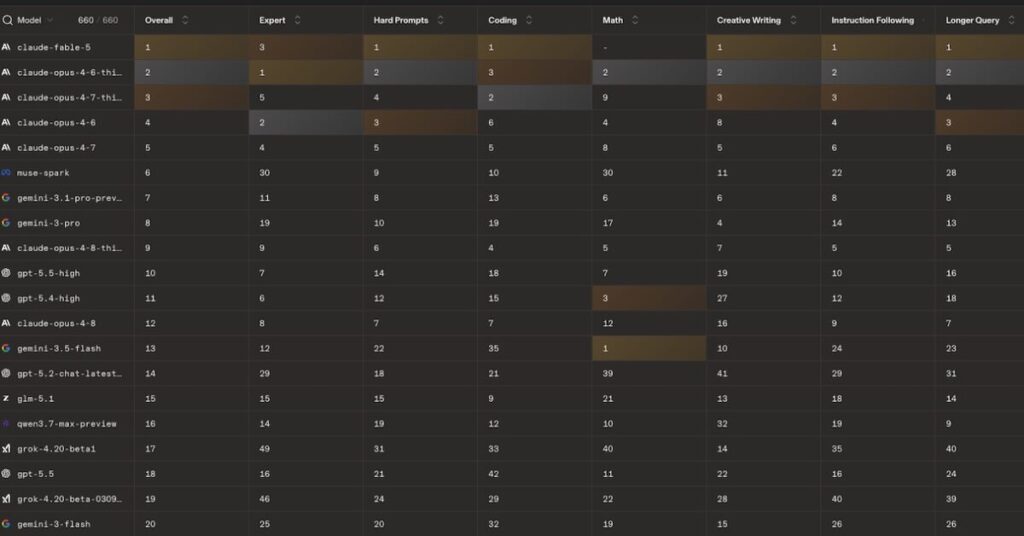
Huit modèles Anthropic dans le top 10
La couverture générale s’arrête au tableau de chasse. Claude Fable 5 en tête, devant les versions « thinking » de Claude Opus 4.6 et 4.7, Claude Opus 4.8 « thinking » qui se glisse neuvième, et au-delà Meta, Google et OpenAI réduits aux places d’honneur. Huit modèles Anthropic sur dix en développement web. Le top 5 monopolisé en analyse d’image. Le constat est réel.
Mais s’arrêter là, c’est confondre le score et le tableau d’affichage. La question intéressante n’est pas « qui gagne ? ». C’est « qui décide qui gagne ? ».
La réponse a changé. Et personne n’en parle.
Arena, ou le sacre de la préférence humaine
Arena (ex-LMArena) n’évalue pas les modèles comme un benchmark académique. Pas de jeu de questions figé, pas de barème fermé. La plateforme organise des duels anonymisés : deux modèles répondent, l’utilisateur vote pour la meilleure réponse sans savoir qui l’a produite. Des milliers de votes plus tard, un classement émerge.
Autrement dit, l’arbitre du marché n’est plus un protocole de test. C’est le ressenti agrégé de milliers d’humains. Le goût, pas seulement la performance brute.
Ce glissement est plus profond qu’il n’y paraît. Pendant des années, on a mesuré l’IA par ses scores sur des épreuves normalisées. FrontierMath, par exemple, où Fable 5 atteint selon Epoch AI 88 % de réussite sur le palier le plus difficile, loin devant les 75 % de GPT-5.5. Ces chiffres comptent encore. Mais ils ne suffisent plus à faire un roi.
Désormais, un modèle « gagne » quand les gens préfèrent lui parler. Ce n’est pas la même exigence. Un benchmark mesure ce qu’un modèle sait faire. Un duel à l’aveugle mesure ce qu’on a envie de réutiliser.
Le couronnement d’un modèle fantôme
Vient alors le détail qui devrait tout faire basculer. Claude Fable 5, le modèle qui domine le classement, a été désactivé par Anthropic. La firme s’est conformée à une directive du gouvernement américain visant à en restreindre l’accès aux seuls ressortissants des États-Unis.
Le numéro un mondial selon la préférence humaine est donc, pour l’essentiel de la planète, inutilisable. Un champion qu’on couronne et qu’on enferme dans le même mouvement.
Posons le paradoxe sans détour :
- Arena dit aux praticiens : voici le meilleur modèle, validé par des milliers de votes humains.
- La réalité géopolitique leur répond : vous n’y avez pas accès.
- Le classement, lui, continue de le faire trôner en tête, comme si de rien n’était.
Hors des États-Unis, ce top 5 vire à la vitrine de produits qu’on ne peut pas acheter. La hiérarchie de référence se découple alors de la réalité d’usage.
Quand l’arbitre et le marché ne parlent plus de la même chose
C’est là que se loge le vrai enjeu. Si l’outil qui fait autorité pour désigner « le meilleur modèle » classe en première position un modèle géo-restreint, sa carte cesse de coïncider avec le territoire que pratique réellement un développeur français, allemand ou japonais.
Concrètement, que fait-on de cette information ? On apprend qu’il existe quelque part un modèle supérieur, qu’on ne pourra ni tester, ni intégrer, ni comparer à ses propres cas d’usage. On hérite d’un classement spectateur, pas d’un classement exploitable.
Cependant, ne jetons pas le bébé avec l’eau du bain. Le reste de la grille demeure précieux. La version « search » de Claude Opus 4.6 tient toujours la tête en recherche web, GPT Image 2 d’OpenAI conserve une nette avance en génération d’images, et des acteurs comme Qwen, Baidu ou GLM s’invitent dans certains top 10. Pour ces modèles-là, accessibles, le vote humain reste un signal utile.
Le problème n’est donc pas Arena. C’est l’écart grandissant entre la frontière technologique et la frontière juridique. Le meilleur modèle et le meilleur modèle disponible deviennent deux objets distincts.
Et si la vraie question n’était plus la performance ?
Pendant une décennie, la course à l’IA s’est jouée sur une seule ligne : qui a le modèle le plus capable. Le classement de juin 2026 suggère qu’une seconde ligne, longtemps ignorée, pèse désormais autant : qui a le droit de l’utiliser.
Un modèle géo-restreint en tête d’un classement mondial, c’est le symptôme d’un marché qui se fragmente non par la technique, mais par la frontière. La préférence humaine s’impose comme juge au moment précis où l’accès, lui, se referme.
Reste à savoir ce que vaut le titre de « meilleur modèle du monde » quand la moitié du monde n’a pas le droit d’en juger par elle-même.

